
hadoop 介绍
物理分布的Hadoop集群
1.1. 分布集群
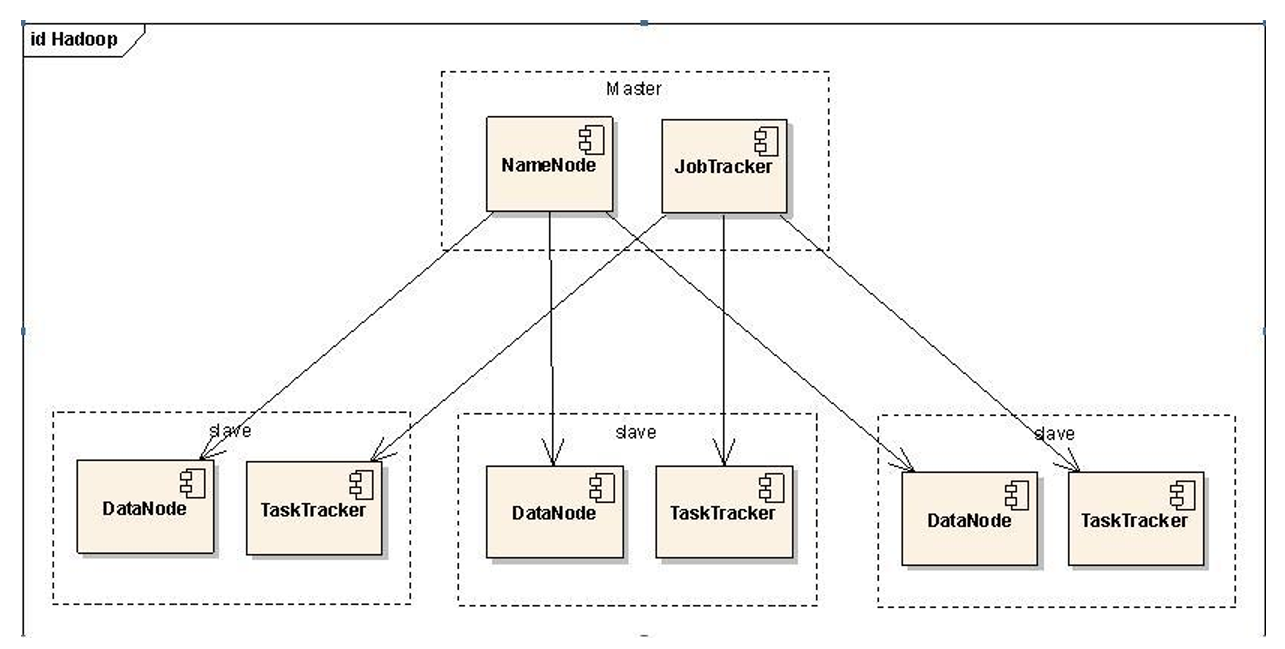
namenode:
- 接受用户操作请求
- 维护文件系统的目录结构
- 管理文件与block之间的关系以及block与datanode之间的关系
datanade:
- 存储文件
- 文件被分成block存储在磁盘上
- 为了保证数据安全,文件会有多个副本
JobTracker:
- 接受客户提交的计算任务
- 把计算任务分配给TaskTrackers执行
- 监控TaskTracker的执行情况
TaskTracker:
- 执行JobTracker分配的计算任务
1.2. 集群结构
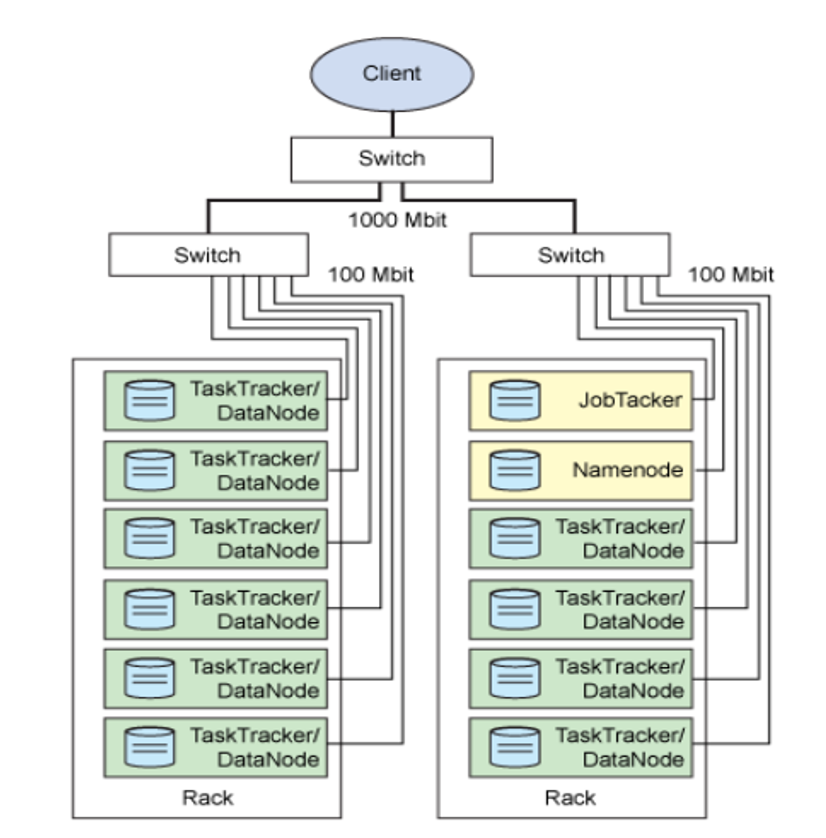
一个集群部署在局域网的环境中,节点(node)之间通过交换机(switch)连接,多台节点以机架(Rack)为单位组织起来,多个机架组成一个数据中心(DC)。
1.3. 物理部署
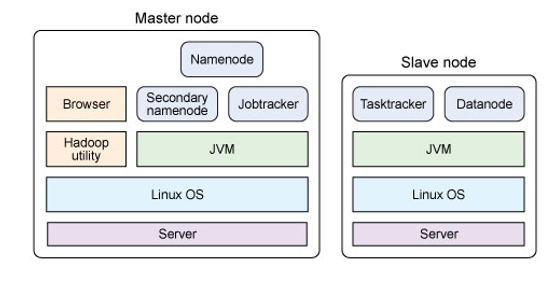
实际的Hadoop系统必须运行在Linux系统上,Namenode会有一个离线备份(Secondary Namenode)
2. HDFS(Hadoop Distributed File System)
HDFS是Hadoop使用的一个主存储系统。HDFS创建多重备份的数据块,并将这些数据快分布在集群中的计算机节点上,以此来实现高可靠性以及高速运算能力。
2.1. 单机操作系统对磁盘空间的管理
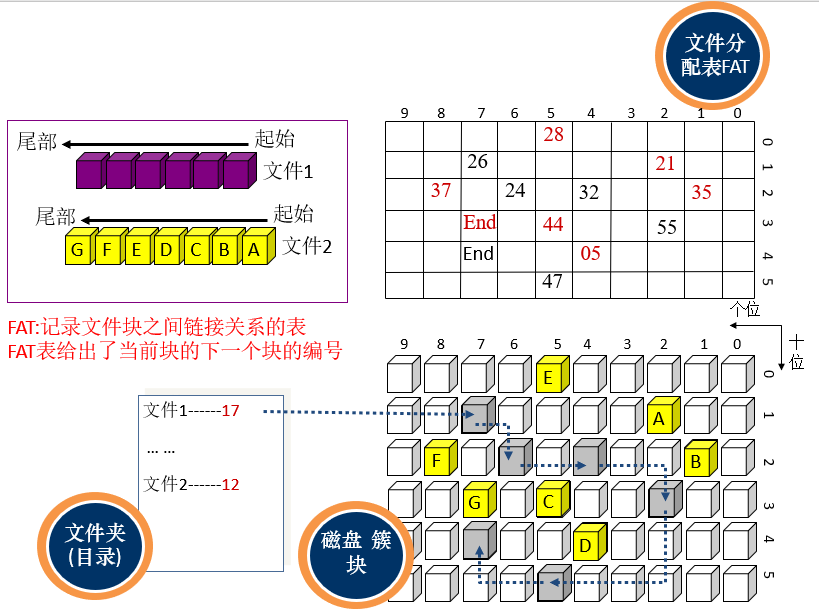
在查找数据时,从文件夹中读取对应文件的第一个数据块的编号,找到该数据之后继续根据FAT表中的数据查找下一个数据块。
2.2. HDFS的主从结构
- 主节点,只有一个:namenode
- 从节点,有很多个:datanode
| Namenode | DataNode |
|---|---|
| 存储元数据 | 存储文件内容 |
| 源数据保存在内存中 | 文件内容保存在磁盘 |
| 保存"文件"-"block"-"datanode"之间的映射关系 | 维护了"block id" 到 "datanode"本地文件的映射关系 |
2.3. HDFS中的文件
文件切分成块(block,默认大小为64M),以块为单位,每个块有多个副本存储在不同的机器上,副本数可以在文件生成是指定(默认为3)。 NameNode是主节点,存储文件的元数据,如文件名、文件目录结构、文件属性(生成时间,副本数,文件权限)、每个文件的块列表以及块所在的DataNode等信息。 DataNode在本地文件系统存储文件块数据以及块数据的校验和。 可以创建、删除、移动或重命名文件,但当文件创建、写入和关闭之后不可以再修改文件内容。
NameNode
NameNode是一个中心服务器,单一节点(简化系统的设计和实现),负责管理文件系统的命名空间以及客户端对文件的访问。 NameNode负责文件元数据的操作,DataNode负责处理文件内容的读写请求,与文件内容相关的数据流不经过NameNode,只会询问NameNode要读写的文件跟哪一个DataNode关联。 副本存放在哪些DataNode上由NameNode来控制,根据全局情况做出放置决定。读取文件时,NameNode尽量让用户读取最近的副本,以此来降低带块的消耗和读取时延。 NameNode全权管理数据块的复制,他周期性地从集群中的DataNode接收Heartbeat信号和Blockreport块状态报告。接收到Heartbeat信号意味着该DataNode节点正常工作,Blockreport包含了该DataNode上所有数据块的列表。
DataNode
一个数据块在DataNode中以本地文件的形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度、块数据的校验和以及时间戳。 DataNode启动后向NameNode注册,通过之后,DataNode周期性(1小时)地向NameNode上报所有的块信息。 Heartbeat信号每3秒一次,HeartBeat返回的结果带有NameNode给该DataNode的命令,如复制数据块到另一台机器或删除某个数据块。如果超过10分钟没有收到某个DataNode的Heartbeat,则认为该节点不可用。 集群运行中可以安全加入和退出一些机器。
3. MapReduce
MapReduce是一种编程模型,它实现了超大集群上的简单数据处理。 MR由两个阶段组成:Map和Reduce。用户可以指定一个map函数来处理一个key-value键值对,从而产生中间键值对集,然后再指定一个reduce函数来合并相同中间key的中间value。 用户只需要实现map()和reduce()两个函数,即可实现分布式计算,用户只需要专注于领域知识,解决领域问题,而无需考虑分布式计算底层细节,如网络通信、任务分发、任务调度等问题。
3.1. MapReduce的架构
主从结构:
- 主节点,只有一个:JobTracker
- 从节点,有很多个:TaskTrackers
JobTracker功能:
- 接受客户提交的计算任务
- 把计算任务分给TaskTrackers执行
- 监控TaskTracker的执行情况
TaskTrackers功能:
- 执行JobTracker分配的任务
MapReduce的执行流程
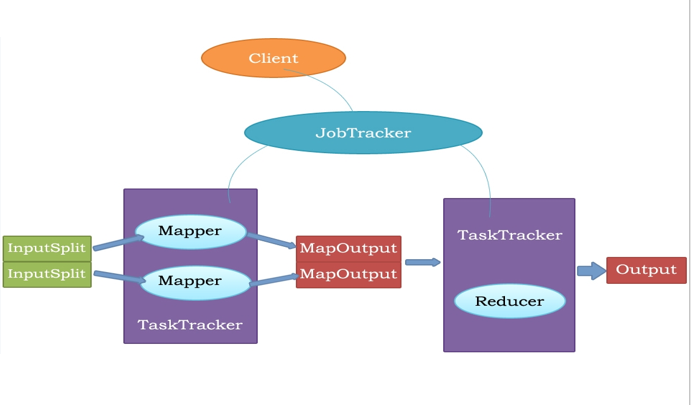
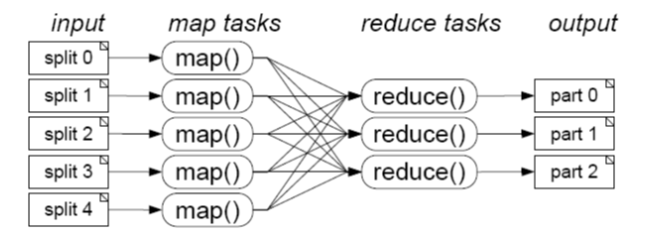
客户端以Job(作业)为单位,向JobTracker提交计算任务,然后JobTracker会将Job划分成等多个并行执行的task,将这些task分配给各个TaskTracker执行。
3.3. MapReduce原理
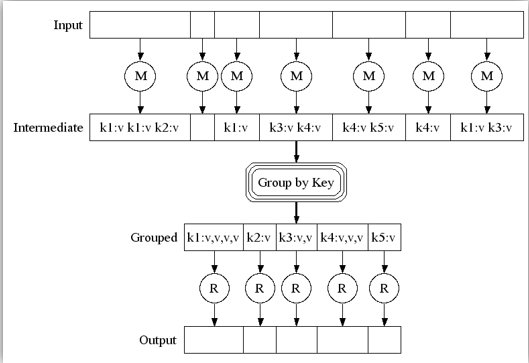
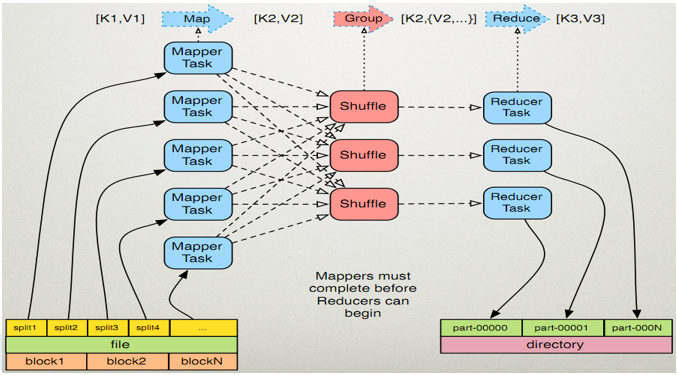
输入的数据被划分成多个split,每个split分配给一个空闲的Mapper Task,由Mapper Task来进行分析处理,得到[key:value],然后对得到的所有[key:value]进行处理,将相同的key的value整合在一起,得到[key:list(value)],最后提交给Reduce Task进行处理,得到最终的输出结果。
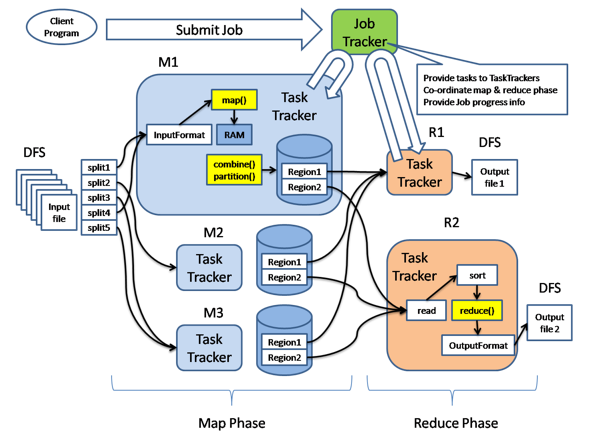
执行步骤:
map任务处理:
- 读取输入文件内容,对输入文件的每一行,解析成key-value对,对每一个键值对调用一次map函数。
- 使用自己的逻辑,对输入的key和value进行处理,转换成新的key-value输出。
- 对输出的key-value进行分区
- 对不同分区的的数据,按照key进行排序、分组。相同key的value放到一个集合当中,构成新的[key:list(value)]。
- (可选)对分组后的数据进行规约。
reduce任务处理:
- 对多个map人物的输出,按照不同分区,通过网络复制到不同的reduce节点。
- 对于多个map任务的输出进行合并、排序。写reduce函数的逻辑,对输入的key-value进行处理,转换成新的key-value输出。
- 把reduce的输出保存到文件中。
Map、Reduce输入输出的键值对格式
| 函数 | 输入键值对 | 输出键值对 |
|---|---|---|
| map() | <k1, v1> | <k2,v2> |
| reduce() | <k2, {v2...}> | <k3,v3> |
3.4. map和reduce函数之间的数据传递示例
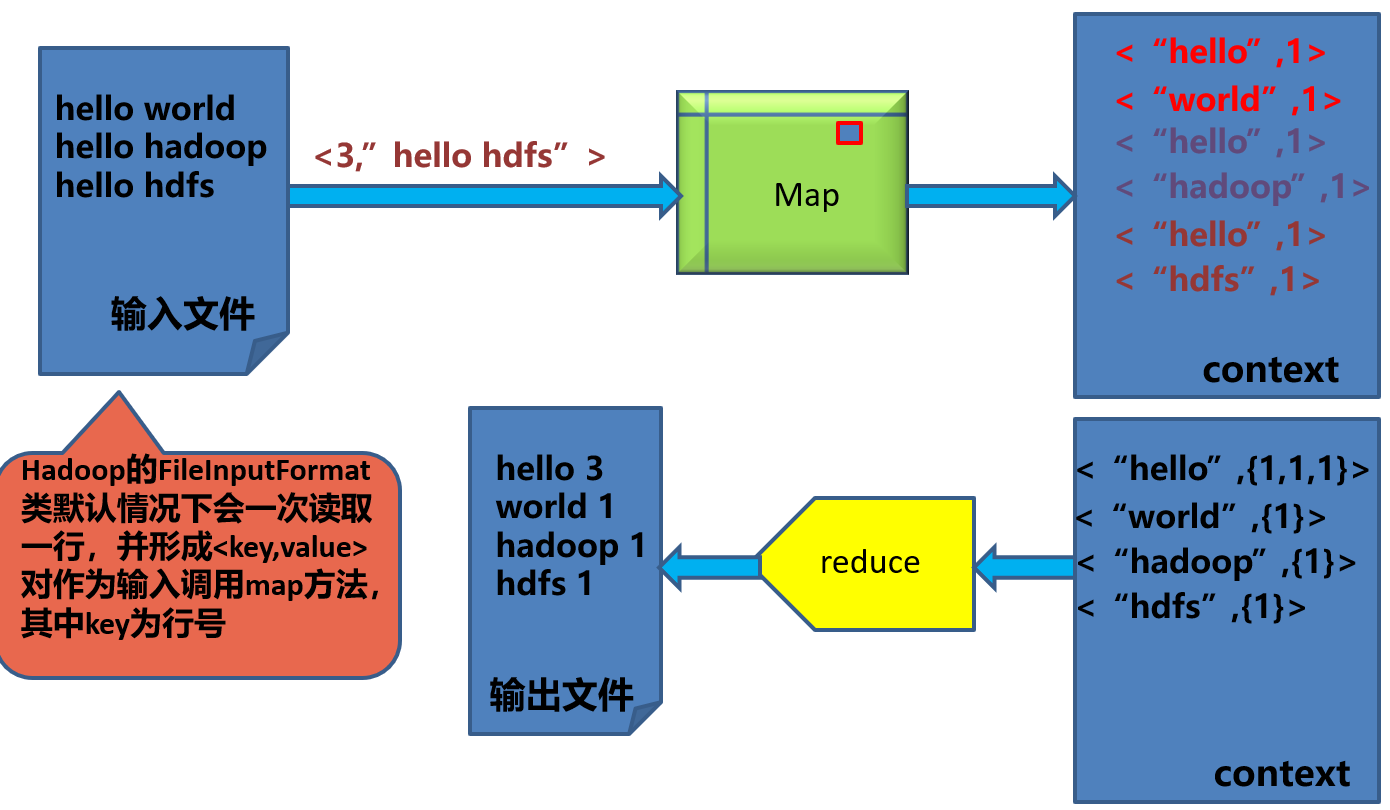
实现Mapper
public class WordCount{
//Mapper类要继承Mapper<Object , Text, Text, IntWritable>
public static class TokenizerMapper extends Mapper<Object , Text, Text, IntWritable>{
//IntWritable、Text是Hadoop API里定义的数据类型
//Text相当于Java中的String
//IntWritable相当于Java中的Integer
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
/**
map函数原型
key和value是输入
context为用户代码与MR系统交互的上下文
**/
public void map(Object key, Text value, Context context) throws IOException, InterruptedExcepition{
//将字符串分割为一个个的单词
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMorTokens()){实现嵌套列表
//将token写入word
word.set(itr.nextToken());
//将键值对<token, 1>写入context,MR框架会将context中的键值对交给Reducer处理
context.write(word,one);
}
}
}
//其他代码
}
实现Reduce
public class WordCount{
//Reduce类要继承Reducer<Text, IntWriable, Text IntWritable>
public static class IntSumReducer extends Reducer<Text, IntWriable, Text IntWritable>{
private IntWritable result = new IntWritable();
/**
reduce函数原型
key和values是输入
context为用户代码与MR系统交互的上下文
**/
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException{
int sum = 0;
//遍历集合中的每个value
for(intWritable val: values){
//对value的值进行累加
sum + = val.get();
}
//得到token的词频
result.set(sum);
//将<token,词频>写入context,由context写到HDFS文件中
context.write(key, result);
}
}
//其他代码
}